Introduction
Parquet data stored in object storage, like AWS S3, has become a standard practice in current data lake architecture. And using Trino with Hive Standalone Metastore to query these data is also a very standard practice, as shown here.
What is less well documented is how to deploy these services in a Kubernetes cluster (for example EKS), and adhere to security best practices when establishing the connection between Trino and S3. One way to do this is to use IAM Roles for Service Accounts (IRSA). This allows us to use a kubernetes service account (used by Trino) to get read/write access to specific S3 buckets, through an IAM policy setup.
This post will guide you through the setup process using mostly Terraform (or OpenTofu if you prefer) and Helm. I have drawn heavy inspiration inspiration from here.
This walkthrough assumes intermediate to advanced familiarly with Terraform (OpenTofu), Kubernetes, EKS (and AWS resources in general) and Helm. Some familiarly with Trino and Hive Metastore is also helpful.
The full code can found in Github.
Hive Metastore Container Image
The Trino team provides official container images and Helm chart we can use, so we are covered there (we will be using them later). but there is no official Hive Standalone Metastore container images. The most updated one I could fined was in this EMR on EKS example.
So lets go through the process of creating the container image for the Hive Metastore we can use. In the repo the Dockerfile and the entry point script is in the folder: metastore/image
As of April 2024, version 4.0.0 of Hive has been release, so we shall uses that (together with Hadoop v3.4.0) to make the image a bit more future-proof, and take advantage of Hadoop upgrades to use AWS SDK v2
Dockerfile
I have chosen to use the Red Hat UBI Image as the base image, which is also what the official Trino image uses:
FROM registry.access.redhat.com/ubi9/ubi-minimal:latest
Then we add build args to set the non-root user:
# user and group IDs to run image as
ARG RUN_AS_USER=1000
ARG RUN_AS_GROUP=1000
and setup up the version to use:
# Versions
ARG HSM_VERSION=4.0.0
ARG HADOOP_VERSION=3.4.0
ARG POSTGRES_DRIVER_VERSION=42.7.3
The dependence now have to install are:
shadow-utilsto create the non-root user and groupjava-17-openjdk-headlessfor the JVM runtimetarandgzipto extract the Hive and Hadoop packages
# update and install java and dependencies
RUN microdnf update -y \
&& microdnf --nodocs install shadow-utils java-17-openjdk-headless tar gzip -y \
&& microdnf clean all -y
Then we setup the non-root user and modifying the ownership of the /opt directory to the non-root user (hsm)
# set up non root user
RUN groupadd -g ${RUN_AS_GROUP} hsm && \
useradd -u ${RUN_AS_USER} -g hsm hsm
# setup opt dir for hsm user
RUN chown -R hsm:hsm /opt
USER hsm
Setting all the relevant environment variable:
# Set Hadoop/HiveMetastore Classpath
ENV JAVA_HOME=/usr/lib/jvm/jre-17
ENV HADOOP_HOME="/opt/hadoop"
ENV METASTORE_HOME="/opt/hive-metastore"
ENV HIVE_HOME="/opt/hive-metastore"
ENV HADOOP_CLASSPATH="${HADOOP_HOME}/share/hadoop/tools/lib/*:${HADOOP_HOME}/share/hadoop/common/lib/*"
Installing Hadoop to the /opt directory:
# Download Hadoop
RUN curl https://dlcdn.apache.org/hadoop/common/hadoop-$HADOOP_VERSION/hadoop-$HADOOP_VERSION.tar.gz \
| tar xz -C /opt/ \
&& ln -s ${HADOOP_HOME}-$HADOOP_VERSION ${HADOOP_HOME} \
&& rm -r ${HADOOP_HOME}/share/doc
Installing Hive Standalone Metastore:
RUN curl https://repo1.maven.org/maven2/org/apache/hive/hive-standalone-metastore-server/${METASTORE_VERSION}/hive-standalone-metastore-server-${METASTORE_VERSION}-bin.tar.gz \
| tar xz -C /opt/ \
&& ln -s /opt/apache-hive-metastore-${METASTORE_VERSION}-bin ${METASTORE_HOME} \
# fix for schemaTool script
&& sed -i -e 's/org.apache.hadoop.hive.metastore.tools.MetastoreSchemaTool/org.apache.hadoop.hive.metastore.tools.schematool.MetastoreSchemaTool/g' ${METASTORE_HOME}/bin/ext/schemaTool.sh
NOTE: As of Hive 4.0.0, there seems to be a bug in the
schemaTool.shscript here, where the Java class is not correct. Hence thesedcommand to fix it to the correct class.
Download and setup Postgres JDBC driver for connection to the :
RUN curl https://repo1.maven.org/maven2/org/postgresql/postgresql/${POSTGRES_DRIVER_VERSION}/postgresql-${POSTGRES_DRIVER_VERSION}.jar \
-o ${METASTORE_HOME}/lib/postgresql-${POSTGRES_DRIVER_VERSION}.jar
Finally we switch to the METASTORE_HOME directory, copy in the entrypoint script and setup CMD to run the entrypoint script
WORKDIR ${METASTORE_HOME}
COPY --chown=hsm:hsm --chmod=775 entrypoint.sh bin/entrypoint.sh
CMD ["bash", "-c", "bin/entrypoint.sh"]
Container Entrypoint
For the entrypoint.sh script, we setup 2 functions, a logging function, taken from here:
function log () {
level=$1
message=$2
echo $(date '+%d-%m-%Y %H:%M:%S') [${level}] ${message}
}
And an initSchema function:
function initSchema () {
log "INFO" "checking DB schemas"
if ${METASTORE_HOME}/bin/schematool -info -dbType postgres
then
log "INFO" "scheme found in DB"
else
log "INFO" "schema not found DB, running initSchema"
${METASTORE_HOME}/bin/schematool -initSchema -dbType postgres
fi
}
this function uses the schemaTool script provided in the Hive Standalone Metastore package, to check if the DB schema and tables are present, and if not, create them.
Finally, we call initSchema and then actually start the Metastore, with some error handling
if initSchema
then
log "INFO" "starting metastore"
${METASTORE_HOME}/bin/start-metastore
else
log "ERROR" "error checking schema or running initSchema"
exit 1
fi
AWS Resources
The the AWS resources that we need are:
- S3 bucket, and associated IAM polices for access.
- The VPC to hold all the resources
- EKS cluster with IAM Role to assume to access the S3 bucket from the EKS cluster
- RDS for the hive metastore
We will create all of these using Terraform (or OpenTofu if you prefer, as I did). In the repo the Terraform file can be found in the folder: terraform/aws-resources.
Setup
First we need to setup the provider versions (AWS), in versions.tf:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "5.43.0"
}
}
}
And set up the input variables in variables.tf (with descriptions):
variable "name" {
type = string
description = "Common name of the S3 bucket, EKS cluster, RDS instance and other resources"
}
variable "region" {
type = string
description = "AWS region to use"
}
variable "vpc_cidr" {
type = string
description = "VPC CIDR block to use"
}
variable "kube_namespace_name" {
type = string
description = "Kubernetes Namespace name where the Trino and Metastore deployments will be done to"
}
variable "kube_sa_name" {
type = string
description = "Kubernetes Service account name, which will be used to access S3 using IAM/IRSA"
}
variable "cluster_endpoint_public_access_cidrs" {
type = list(string)
description = "List of CIDR blocks which can access the Amazon EKS public API server endpoint"
}
variable "kubeconfig_location" {
type = string
description = "Location to save the Kubeconfig file to"
}
variable "enable_eks" {
type = bool
default = true
description = "Turn on or off the EKS resources"
}
variable "enable_rds" {
type = bool
default = true
description = "Turn on or off the RDS resources"
}
For the variable cluster_endpoint_public_access_cidrs, we need to specify the CIDR blocks/IP addresses of the machines from which we need be able to connect to the EKS API endpoint (to run kubectl commands). This connection would be needed to deploy the Kubernetes resources later. So we should put in the CIDR block/IP address of the machine that we are using ot run these terraform scripts from. We would also be reusing this to allow IPs that can access the Metastore RDS instance.
This is the example terraform.tfvars I used to set the variable values (this file should not be committed to git, as per best practices):
name = "trino-on-eks"
region = "ap-southeast-1"
vpc_cidr = "10.0.0.0/24"
kube_namespace_name = "trino"
kube_sa_name = "s3-access"
cluster_endpoint_public_access_cidrs = ["your_ip_here/32"]
kubeconfig_location = "../../local/kubeconfig.yaml"
enable_eks = true
enable_rds = true
Of course do put in your own IP for cluster_endpoint_public_access_cidrs.
All the main resources are defined in the main.tf file,
First we get the information of all the availability zones (azs) in the our region:
data "aws_availability_zones" "available" {}
Then we calculate the CIDR blocks for the azs using the azs information, and setup the common tags in the locals:
locals {
azs = slice(data.aws_availability_zones.available.names, 0, 3)
tags = {
role = var.name
}
}
Then we setup the AWS provider with the region value from locals:
provider "aws" {
region = var.region
}
S3 Bucket
For the S3 resource, we first setup the main S3 bucket:
resource "aws_s3_bucket" "trino_on_eks" {
bucket = var.name
tags = local.tags
}
We then create the policy document which specifies read/write and list permission on that bucket only:
data "aws_iam_policy_document" "trino_s3_access" {
statement {
actions = [
"s3:ListBucket"
]
resources = [aws_s3_bucket.trino_on_eks.arn]
}
statement {
actions = [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject"
]
resources = ["${aws_s3_bucket.trino_on_eks.arn}/*"]
}
}
And assign this policy document to the actual IAM policy and create that:
resource "aws_iam_policy" "trino_s3_access_policy" {
name = "trino_s3_access_policy"
path = "/"
policy = data.aws_iam_policy_document.trino_s3_access.json
}
This policy will be how the service in EKS (Trino and Hive metastore) will get access to the S3 bucket, as we will see later.
VPC
Using the VPC module we create the VPC, using the values from locals:
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
name = var.name
cidr = var.vpc_cidr
azs = local.azs
public_subnets = [for k, v in local.azs : cidrsubnet(var.vpc_cidr, 4, k)]
enable_dns_support = true
enable_dns_hostnames = true
map_public_ip_on_launch = true
tags = local.tags
}
For the sake of simplicity and to save cost, we are only creating public subnets. However it is recommended to use private subnet with a NAT gateway for th EKS cluster and RDS.
EKS Cluster resources
Using the EKS module, we create the EKS cluster in the public subnets of the VPC we created:
module "eks" {
count = var.enable_eks ? 1 : 0
source = "terraform-aws-modules/eks/aws"
version = "~> 20.0"
cluster_name = var.name
cluster_version = "1.29"
cluster_endpoint_private_access = true
cluster_endpoint_public_access = true
cluster_endpoint_public_access_cidrs = var.cluster_endpoint_public_access_cidrs
cluster_addons = {
coredns = {
most_recent = true
}
kube-proxy = {
most_recent = true
}
vpc-cni = {
most_recent = true
}
}
vpc_id = module.vpc.vpc_id
subnet_ids = module.vpc.public_subnets
eks_managed_node_groups = {
trino = {
min_size = 1
max_size = 3
desired_size = 1
instance_types = ["t3.medium"]
capacity_type = "SPOT"
}
}
# Cluster access entry
# To add the current caller identity as an administrator
enable_cluster_creator_admin_permissions = true
tags = local.tags
}
I have chosen to use t3.medium spot instances, with a max size of 3. As hinted when creating the variables, To be able to access this cluster’s API endpoint (to run kubectl commands), we have to set cluster_endpoint_public_access to true and specify the public access CIDRs in cluster_endpoint_public_access_cidrs, which is coming from the variables.
Then we create the IAM role that connects the IAM policies for the S3 bucket access we created before to a service account in he EKS cluster. We can use this submodule:
module "trino_s3_access_irsa" {
count = var.enable_eks ? 1 : 0
source = "terraform-aws-modules/iam/aws//modules/iam-assumable-role-with-oidc"
create_role = true
role_name = "trino_s3_access_role"
provider_url = module.eks[0].oidc_provider
role_policy_arns = [aws_iam_policy.trino_s3_access_policy.arn]
oidc_fully_qualified_subjects = ["system:serviceaccount:${var.kube_namespace_name}:${var.kube_sa_name}"]
}
This assigns the service account specified in var.kube_sa_name in the namespace specified in var.kube_namespace_name the permissions to assume this created role (through the cluster’s OIDC provider), which in turn has been assigned the S3 bucket access polices created before.
And finally we need to save the kubeconfig file for access to the cluster. For this first we setup the kubeconfig yaml template:
apiVersion: v1
preferences: {}
kind: Config
clusters:
- cluster:
server: ${endpoint}
certificate-authority-data: ${clusterca}
name: ${cluster_name}
contexts:
- context:
cluster: ${cluster_name}
user: ${cluster_name}
name: ${cluster_name}
current-context: ${cluster_name}
users:
- name: ${cluster_name}
user:
exec:
apiVersion: client.authentication.k8s.io/v1beta1
command: aws
args:
- --region
- ${region}
- eks
- get-token
- --cluster-name
- ${cluster_name}
- --output
- json
In the repo this is located at terraform/aws-resources/templates/kubeconfig.tpl.
This template is used to create the final kubeconfig file using the local_sensitive_file resource:
resource "local_sensitive_file" "kubeconfig" {
count = var.enable_eks ? 1 : 0
content = templatefile("${path.module}/templates/kubeconfig.tpl", {
cluster_name = module.eks[0].cluster_name,
clusterca = module.eks[0].cluster_certificate_authority_data,
endpoint = module.eks[0].cluster_endpoint,
region = var.region
})
filename = var.kubeconfig_location
}
The location where this is saved to is set by the variable kubeconfig_location. Do be careful not to save it where it might get accidentally committed and pushed to git.
RDS Resources for Metastore
As the Metastore needs a DB, I chose to use RDS postgres as the simple straightforward solution. First we create a random password, and save it to AWS Secret Manager
resource "random_password" "rds_password"{
length = 16
special = true
override_special = "_!%^"
}
resource "aws_secretsmanager_secret" "rds_password" {
name = "trino-on-eks-rds-password"
}
resource "aws_secretsmanager_secret_version" "rds_password" {
secret_id = aws_secretsmanager_secret.rds_password.id
secret_string = random_password.rds_password.result
}
Then we setup the DB subnets, which is basically the public subnets of the VPC we created:
resource "aws_db_subnet_group" "trino_on_eks" {
name = var.name
subnet_ids = module.vpc.public_subnets
tags = local.tags
}
Similar to our EKS cluster, we are putting the RDS instance in the public subnet, for simplicity and cost. We should ideally be putting this too in a private subnet behind a NAT gateway.
Then we setup the security group which should only allow ingress from within the VPC, and from our own machine (to query the RDS to check). Thus the ingress CIDR blocks will be combination of the VPC CIDR and reusing the variable cluster_endpoint_public_access_cidrs for the local machine:
resource "aws_security_group" "trino_on_eks_rds" {
name = "trino-on-eks-rds"
vpc_id = module.vpc.vpc_id
ingress {
from_port = 5432
to_port = 5432
protocol = "tcp"
cidr_blocks = concat([var.vpc_cidr], var.cluster_endpoint_public_access_cidrs)
}
egress {
from_port = 5432
to_port = 5432
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
tags = local.tags
}
Then we setup some DB parameter:
resource "aws_db_parameter_group" "trino_on_eks_rds" {
name = var.name
family = "postgres16"
parameter {
name = "log_connections"
value = "0"
}
}
and finally the RDS instance itself:
resource "aws_db_instance" "trino_on_eks_rds" {
count = var.enable_rds ? 1 : 0
identifier = var.name
instance_class = "db.t4g.micro"
allocated_storage = 10
engine = "postgres"
engine_version = "16.2"
db_name = "trino_on_eks"
username = "trino_on_eks"
password = random_password.rds_password.result
db_subnet_group_name = aws_db_subnet_group.trino_on_eks.name
vpc_security_group_ids = [aws_security_group.trino_on_eks_rds.id]
parameter_group_name = aws_db_parameter_group.trino_on_eks_rds.name
publicly_accessible = true
skip_final_snapshot = true
}
With all these resources, we are now ready to deploy our application into the EKS cluster.
Kubernetes (EKS) Resources
We separate the kubernetes resources from the AWS (infra) resources, to avoid dependency issues between the AWS and Kubernetes providers.
So, although we are still using terraform to deploy the kube resources, these will be done in a separate folder, with a separate state. In the repo these can be found in: terraform/kube-resources.
Setup
As before, we start with defining the provider versions in the versions.tf file:
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "5.43.0"
}
kubernetes = {
source = "hashicorp/kubernetes"
version = "~> 2.27.0"
}
}
}
We are still defining the AWS provider, because we will use these to get information about the EKS cluster and RDS instance we setup previously.
Then we set up the input variables in variables.tf (with descriptions):
variable "name" {
type = string
description = "Common name of the S3 bucket, EKS cluster, RDS instance and other resources"
}
variable "region" {
type = string
description = "AWS region to use"
}
variable "kube_namespace_name" {
type = string
description = "Kubernetes Namespace name where the Trino and Metastore deployments will be done to"
}
variable "kube_sa_name" {
type = string
description = "Kubernetes Service account name, which will be used to access S3 using IAM/IRSA"
}
With example terraform.tfvars (as before, careful not to commit this):
name = "trino-on-eks"
region = "ap-southeast-1"
kube_namespace_name = "trino"
kube_sa_name = "s3-access"
The values should match what was set as variable values in the AWS resources Terraform.
Then, in the main.tf, with the AWS provider, we get the following info:
- EKS cluster general and auth info:
data "aws_eks_cluster" "trino_on_eks" {
name = var.name
}
data "aws_eks_cluster_auth" "trino_on_eks" {
name = var.name
}
- Info about the role that can be used to access the S3 bucket
data "aws_iam_role" "trino_s3_access_role" {
name = "trino_s3_access_role"
}
- RDS DB general and auth information:
data "aws_db_instance" "trino_on_eks_rds" {
db_instance_identifier = var.name
}
data "aws_secretsmanager_secret" "rds_password" {
name = "trino-on-eks-rds-password"
}
data "aws_secretsmanager_secret_version" "rds_password" {
secret_id = data.aws_secretsmanager_secret.rds_password.id
}
So with the EKS cluster we can setup the kubernetes and helm providers:
provider "kubernetes" {
host = data.aws_eks_cluster.trino_on_eks.endpoint
cluster_ca_certificate = base64decode(data.aws_eks_cluster.trino_on_eks.certificate_authority[0].data)
token = data.aws_eks_cluster_auth.trino_on_eks.token
}
provider "helm" {
kubernetes {
host = data.aws_eks_cluster.trino_on_eks.endpoint
cluster_ca_certificate = base64decode(data.aws_eks_cluster.trino_on_eks.certificate_authority[0].data)
token = data.aws_eks_cluster_auth.trino_on_eks.token
}
}
Namespace
The namespace is the first kubernetes resource we create, to hold all the other resources:
resource "kubernetes_namespace" "trino" {
metadata {
name = var.kube_namespace_name
}
}
Service Account
Then we create the service account, which will be the once that will assume the role created previously to allow access to the S3 bucket. This is done by annotating the service account resource with the role ARN.
resource "kubernetes_service_account" "trino_s3_access_sa" {
depends_on = [kubernetes_namespace.trino]
metadata {
name = var.kube_sa_name
namespace = var.kube_namespace_name
annotations = {
"eks.amazonaws.com/role-arn" = data.aws_iam_role.trino_s3_access_role.arn
}
}
}
We will then make sure that the Trino and Metastore deployment use these service account, which will result in EKS Pod Identity Webhook injecting environment variables and secrets volumes to allow the AWS SDKs in the applications to use sts:AssumeRoleWithWebIdentity credential provider to assume the role, authenticate and access the S3 bucket, as descripted in more details here and here.
Metastore Deployment
We will now deploy the Metastore using a Helm chart, which in the repo can be found in the folder: metastore/helm-chart. I will not be going into the details of creating this Helm chart here, as it quite involved, and deserver is own writeup. Do let me know if you would like me to do that write up.
We will use the helm_release Terraform resource to deploy it, with the appropriate values:
resource "helm_release" "metastore" {
depends_on = [kubernetes_service_account.trino_s3_access_sa]
name = "metastore"
namespace = var.kube_namespace_name
chart = "../../metastore/helm-chart"
set {
name = "image"
value = "ghcr.io/binayakd/metastore:4.0.0-hadoop-3.4.0"
}
set {
name = "dbUrl"
value = "jdbc:postgresql://${data.aws_db_instance.trino_on_eks_rds.endpoint}/${data.aws_db_instance.trino_on_eks_rds.db_name}"
}
set {
name = "dbUser"
value = data.aws_db_instance.trino_on_eks_rds.master_username
}
set {
name = "dbPassword"
value = data.aws_secretsmanager_secret_version.rds_password.secret_string
}
set {
name = "dbDriver"
value = "org.postgresql.Driver"
}
set {
name = "s3Bucket"
value = "s3://trino-on-eks"
}
set {
name = "serviceAccountName"
value = var.kube_sa_name
}
}
The first value set is the Metastore image, the creation of which we went through previously.
NOTE: I have built and pushed this image to Github registry. However, since it has full Hadoop binaries in it, the image size is pretty huge, and pulling it using public access from Github will take very long. It would be better to build it yourself, and push it into your own container registries.
The next few values are set for access to the RDS instance (connection endpoint, DB name, username and password). These are all gotten from the AWS data resources defined in the setup section.
And finally we set the S3 bucket name, and the service account to use for the Metastore deployment.
Trino Deployment
For the Trino deployment, we will be using the Official Helm charts. We first need to define the extra chart values, which we define in the file terraform/kube-resources/trino-helm-values.yaml:
server:
workers: 1
additionalCatalogs:
s3_hive: |-
connector.name=hive
hive.metastore.uri=thrift://metastore:9083
fs.native-s3.enabled=true
s3.region=ap-southeast-1
Here, we are setting the trino workers to 1 (since we will not be doing any heavy querying), and adding our Metastore as a an additional Hive catalog, with all the connection details, based on the documentation here.
Setting fs.native-s3.enabled=true allows Trino to directly access the files in S3 without having to rely on the Hive libraries in the Metastore instance, as described here
With the values yaml setup, we can again use the helm_release resource to deploy the main Trino cluster:
resource "helm_release" "trino" {
name = "trino"
namespace = var.kube_namespace_name
repository = "https://trinodb.github.io/charts"
chart = "trino"
values = [
"${file("trino-helm-values.yaml")}"
]
set {
name = "serviceAccount.name"
value = var.kube_sa_name
}
}
Again here we are additionally setting the service account to allow Trino access to the S3 bucket.
With all that deployed we should have all the resources deployed for a working setup.
Testing the Setup
Kubectl Context Setup and Connection Test
First step is to check if all the Kube resources have are deployed properly and running. To do this, first we ensure out kubecontex is setup, by setting up the KUBECONFIG env variable to point to the location where we have set terraform to save it. so for example, I have set it to save to a folder called local in the root of my repo (which I have added to my gitignore). So we can setup the context in the terminal like this:
cd ./local
export KUBECONFIG=./kubeconfig.yaml
Then we can check if the pods are running using kubectl get pods command:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
metastore-796bb9dc7d-bl45s 1/1 Running 0 5m30s
trino-coordinator-58ddd58b6-t2v7g 1/1 Running 0 5m30s
trino-worker-69ff875bbb-qs4mc 1/1 Running 0 5m30s
You should see one metastore pod, one Trino coordinator pod, and a number of Trino worker pods (in our case 1)
Since we have not setup any ingress or loadbalancer resource to access Trino (which I will leave as an exercise for another time), we can access it using the kubectl port-forward command:
kubectl port-forward service/trino 8080
This will allow us to access the Trino endpoint on our local machine on port 8080.
So, using your faviroute DB client (I am using Dbeaver), we can connect to Trino:
Once its successfully connected, we can see the s3_hive catalog (together with some default ones), which we configured in the Trino Helm values to connect to the Metastore:
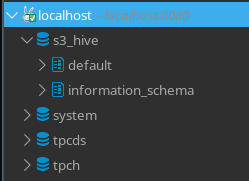
Loading Sample Data
So now that we have out Trino connection setup, we need some data to run queries on. We could either use Trino to write some data into out datastore, or we can register some existing files in S3 as an external table.
Lets do the latter, using the well-known Iris Dataset. I will use the parquet version, but CSV also works.
So we load it into our S3 bucket:
$ aws s3 cp ./iris.parquet s3://trino-on-eks/iris.parquet/iris.parquet
upload: ./iris.parquet to s3://trino-on-eks/iris.parquet/iris.parquet
NOTE: the file has to be in a “subfolder” level in S3, as Trino will only be able to create the table at the folder level. In this case the table will be created in teh path
s3://trino-on-eks/iris.parquet
Now that we have some data in out S3 bucket, we first create a schema, with a location popery of the S3 bucket:
CREATE SCHEMA s3_hive.test
WITH (location = 's3a://trino-on-eks/')
NOTE: The S3 URL starts with
s3a(nots3) which is used by a spacial S3 client which is actually part of the hadoop-aws module.
Then we create the actual table that registers the parquet file location:
CREATE TABLE s3_hive.test.iris (
id DOUBLE,
sepal_length DOUBLE,
sepal_width DOUBLE,
petal_length DOUBLE,
petal_width DOUBLE
)
WITH (
format = 'PARQUET',
external_location = 's3a://trino-on-eks/iris.parquet'
)
Finally, when we do a select query on this table:
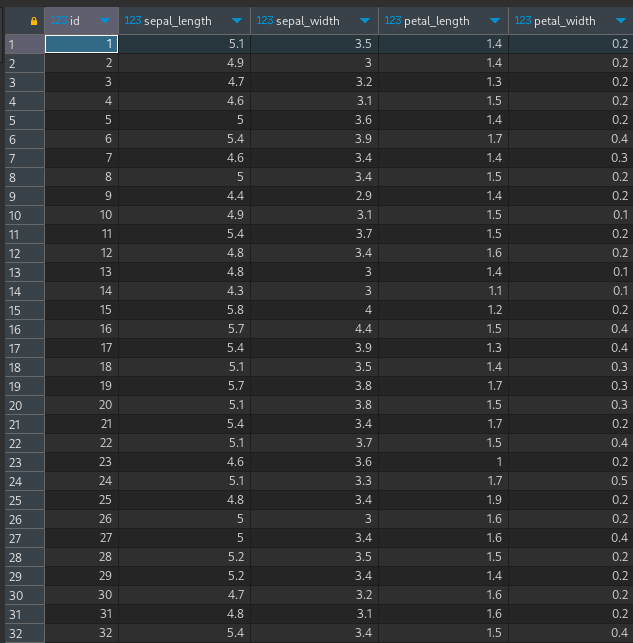
select * from s3_hive.test.iris;
We can see the results: